
Semantic Risk Analysis
COMPANY/SURFACE
Large, multi-product technology organizations operating at scale; particularly those integrating research, product development, and AI-enabled systems.
Applied research work addressing how unclear language degrades decision-making, research, and AI systems at scale.
THE PROBLEM
In large technology organizations operating at scale, clarity was often treated as implicit rather than designed. Goals were framed broadly, research questions left open to interpretation, and definitions shifted as work moved across teams. Over time, this ambiguity became embedded in workflows, metrics, and technical systems, making decisions harder to trace and insights harder to reuse. As these organizations increasingly relied on data-driven decision-making and AI-enabled systems, unclear inputs and inconsistent language introduced compounding operational risk that was difficult to detect until issues surfaced downstream.
THE SOLUTION
The work focused on making visible how ambiguity entered AI-related work in practice, particularly through misunderstandings of how large language models behave. Teams often treated LLMs as deterministic systems or neutral knowledge stores, assuming that vague goals, loosely defined prompts, or inconsistent labels would average out. In reality, these inputs directly shaped model behavior, producing outputs that appeared fluent but were misaligned, difficult to evaluate, or unsafe to reuse. Through applied research, diagnostic reviews, and facilitated discussions, the work traced how language moved from planning documents into prompts, labels, evaluation criteria, and downstream decisions ultimately helping teams clarify definitions, bound intent, and align constraints so qualitative goals, quantitative signals, and system behavior stayed connected.
CLIENT
Enterprise and platform organizations with distributed teams, complex decision-making structures, and increasing reliance on research and AI to guide strategy and execution.
INDUSTRY
Multi-engagement, longitudinal
TOOLS
Qualitative interviews
Diagnostic analysis
Language audits
Facilitated workshops
Cross-system synthesis
Executive readouts
ROLE
Consulting and advisory engagements
DURATION
Multi-engagement, longitudinal
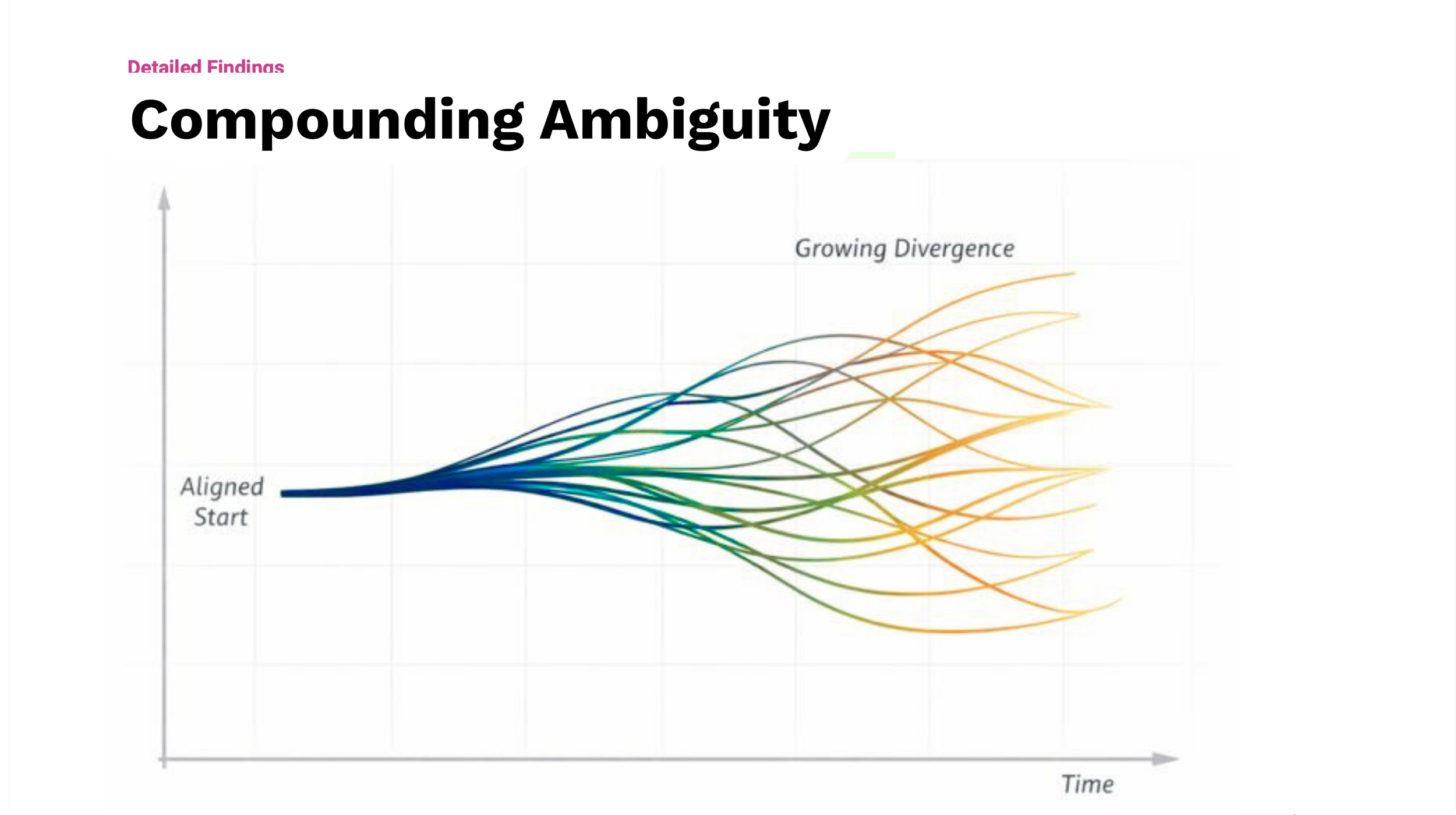
Ambiguity compounds faster than teams realize.
Ambiguity didn’t surface as a single failure, but as a pattern observed across teams and initiatives. Loosely defined goals, inconsistent terminology, and assumptions about how AI systems would behave accumulated over time, making decisions harder to trace and work harder to align. As these issues moved through research, planning, and implementation, they introduced risk that was difficult to see in isolation. This case study documents how those breakdowns were identified in practice and how applied research was used to make them visible, discussable, and addressable before they propagated further.
INVESTIGATE
Before proposing interventions, I began with an investigative phase focused on understanding how clarity was actually functioning across research, product, and AI-related work. Rather than starting from frameworks or best practices, I worked backward from observed breakdowns—missed handoffs, disputed metrics, fragile models, and recurring confusion—to identify where ambiguity was entering systems and how it was being carried forward. The goal at this stage wasn’t to fix anything, but to build a grounded picture of how meaning was being created, interpreted, and lost over time.
Retrospective Synthesis: I reviewed existing research outputs, planning documents, metrics definitions, and system artifacts to understand how goals and concepts were being framed and reused. This made it possible to distinguish between deliberate decisions, inherited language, and assumptions that had quietly solidified without scrutiny—highlighting where ambiguity had become embedded rather than explicitly chosen.
Stakeholder sensemaking: I facilitated conversations with cross-functional partners to surface how different teams understood key concepts, success criteria, and system behavior. These discussions revealed where shared language masked divergent interpretations, where confidence outpaced evidence, and where teams believed alignment existed simply because the same terms were in use. The aim was not alignment, but visibility into which assumptions were doing real work.
Applied observation across in-flight work: I examined how language moved through live initiatives—how research questions informed metrics, how metrics shaped AI inputs, and how outputs were evaluated and acted on. This helped surface recurring patterns where ambiguity was introduced early, amplified downstream, and difficult to trace once embedded in systems. These observations formed the basis for articulating concrete claims about how clarity failures manifested in practice.

FRAME
Before proposing interventions, this work focused on articulating the underlying claims the organization was already making about how clarity operates across research, product, and AI-related work. These claims were rarely stated directly, but were embedded in how goals were written, how research was generalized, how metrics were defined, and how model outputs were evaluated and trusted. The statements below represent those claims in their clearest form. They functioned as framing artifacts: a shared set of assumptions that made the logic behind existing practices explicit and testable. Rather than treating ambiguity as an abstract concern, this framing work surfaced concrete beliefs about language, evidence, and system behavior that were already shaping decisions and outcomes.
Shared terminology implies shared understanding.
Vague goals preserve flexibility without introducing risk.
Research findings remain valid when generalized across contexts.
Alignment can be inferred when teams use the same language.
Metrics accurately reflect the intent behind qualitative goals.
Model performance can be evaluated independently of how inputs are framed.
Fluent system output is a reliable proxy for correctness or usefulness.
8. Ambiguity introduced early will be corrected downstream.
9. Labels and categories stabilize meaning over time.
10. Consistency in reporting implies consistency in interpretation.
11. AI systems will compensate for underspecified inputs.
12. Disagreements reflect execution issues rather than framing issues.
13. Reuse of artifacts preserves their original meaning.
14. Clarity issues surface quickly when they matter.
TARGET
In this phase, targeting meant narrowing attention to a small set of high-leverage clarity surfaces—areas where ambiguity was most likely to compound into downstream risk. Rather than attempting to improve clarity everywhere, the work focused on identifying where meaning had the greatest operational impact and where misalignment was hardest to detect once embedded. Each target represented a distinct way clarity was assumed to function across research, metrics, and AI systems, allowing the work to examine which assumptions held under scrutiny and which required intervention.
INTENT DEFINITION
Targeting began by isolating how goals and success criteria were defined. This dimension focused on whether intent was explicitly bounded or left open to interpretation, and how those choices shaped downstream research questions, metrics, and system behavior. Treating intent definition as its own target made it possible to assess where ambiguity was introduced at the source.
EVIDENCE TRANSLATION
This dimension targeted how qualitative understanding was translated into measurable signals. By separating evidence translation from decision-making itself, the work examined whether research insights, labels, and metrics preserved their original meaning as they moved across teams and tools—or whether interpretation drifted as artifacts were reused.
SYSTEM INTERPRETATION
This target focused on how technical systems were expected to behave under ambiguity. By isolating assumptions about AI and automated decision-making, the work examined whether teams believed systems would compensate for underspecified inputs, and how those beliefs influenced prompt design, labeling practices, and evaluation criteria.
DECISION CONFIDENCE
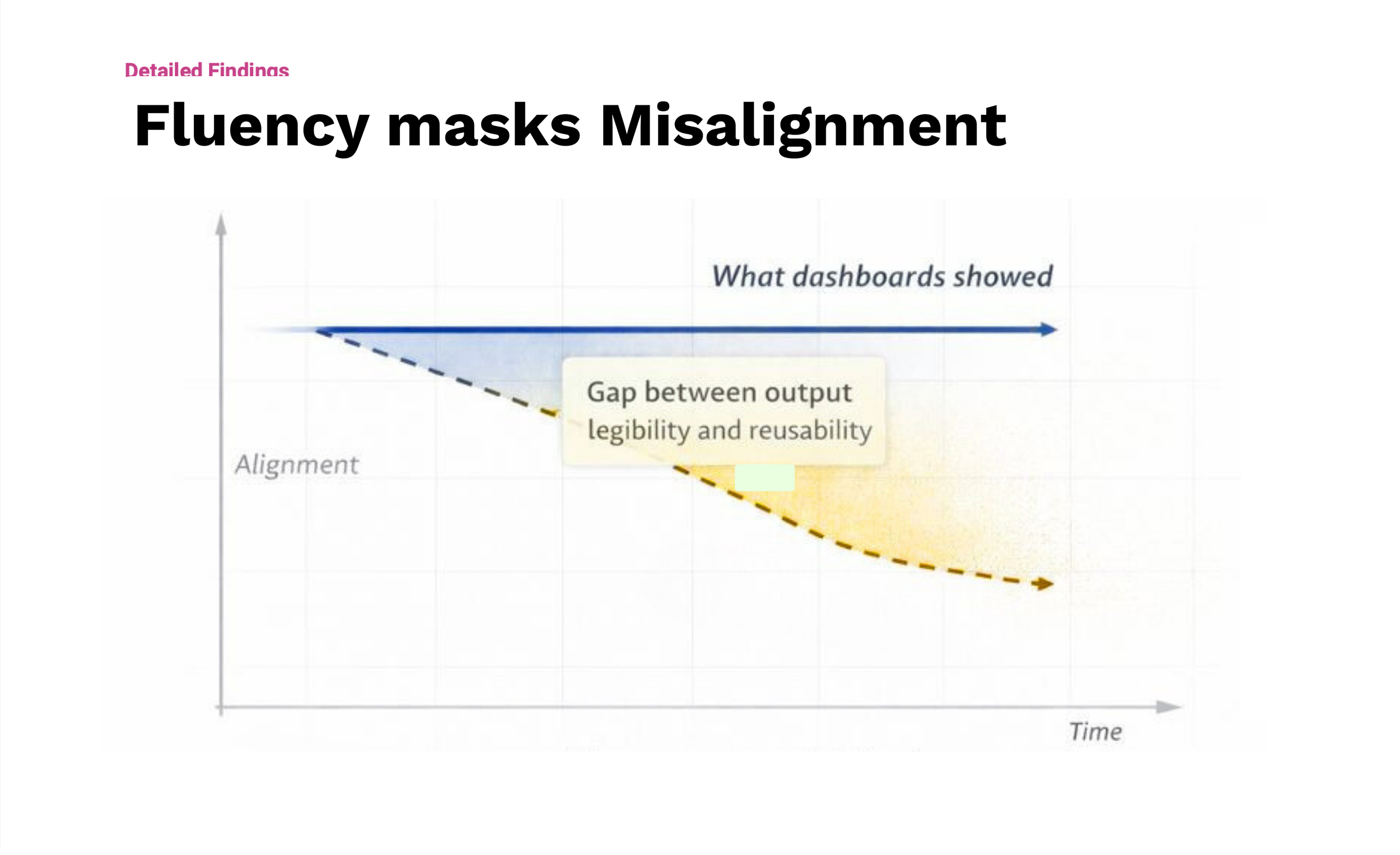
This dimension targeted how confidence was established and reinforced. Separating confidence from correctness made it possible to examine whether trust was grounded in traceable evidence or inferred from fluent output, stable dashboards, or consensus language—particularly in AI-assisted workflows.
ACCOUNTABILITY AND TRACEABILITY
This dimension targeted whether decisions, outputs, and system behavior could be meaningfully traced back to their originating intent and evidence. By isolating traceability as its own concern, the work examined where rationales were preserved, where they were lost, and how that loss affected teams’ ability to explain outcomes, course-correct, or responsibly scale AI-assisted decisions. Treating traceability as a distinct target made it possible to surface gaps that were invisible when confidence or performance was assessed in isolation.

REUSE AND PROPAGATION
The final target focused on how meaning persisted over time. By isolating reuse as a dimension of value, the work examined whether artifacts retained their intent as they were repurposed across projects, teams, and systems, or whether small shifts accumulated into structural misalignment.
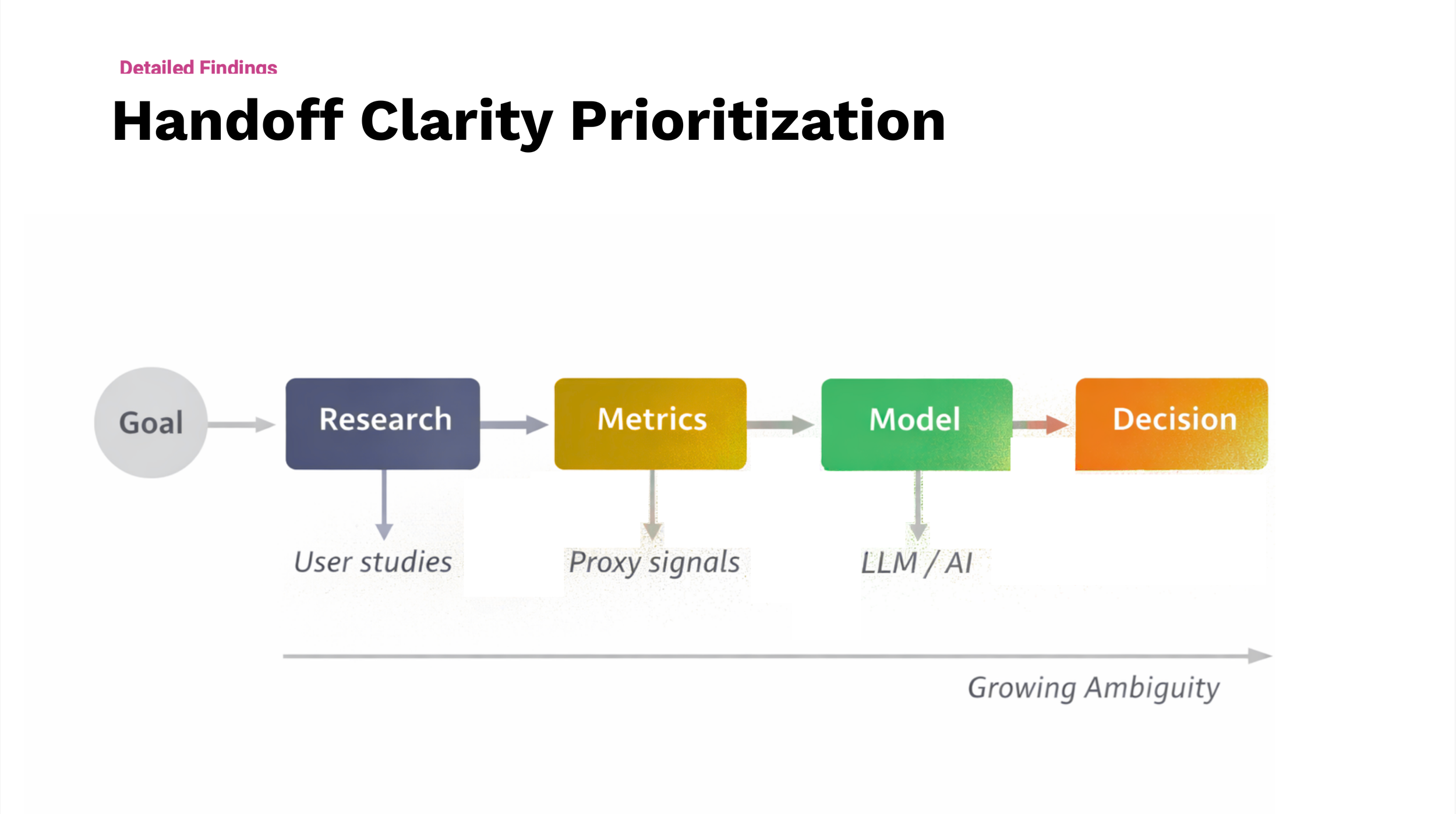
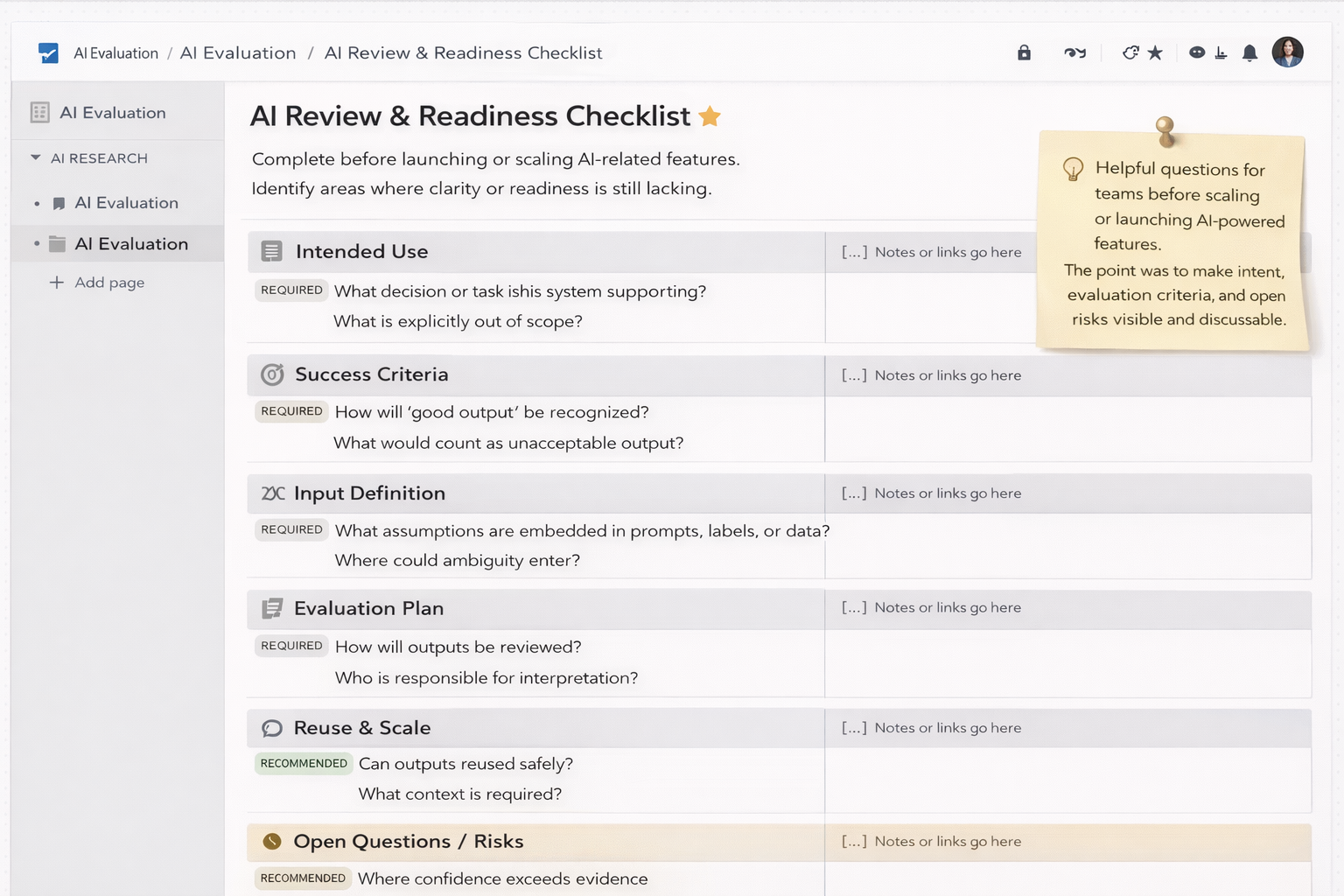
A closer look at artifacts used to examine how ambiguity enters AI work


MAKE PATTERNS VISIBLE ACROSS THE SYSTEM
Once examples of ambiguity were surfaced across prompts, labels, evaluation criteria, and downstream decisions, the work shifted to organizing them into a structure that showed how they accumulated over time. Rather than treating each issue as an isolated failure, this phase mapped how small imprecisions in language propagated across planning documents, experimentation, evaluation, and reuse. Seeing these patterns together helped teams recognize ambiguity as a systemic condition—not a series of one-off mistakes, and made the compounding effects legible.
DIFFERENTIATE LOCAL CONFUSION FROM SYSTEMIC RISK
The organizing phase also distinguished between ambiguity that created short-term friction and ambiguity that introduced long-term risk. Some misunderstandings primarily slowed teams down or caused disagreement; others quietly undermined evaluation, reuse, and trust by allowing confidence to outpace evidence. Separating these helped teams prioritize where clarity mattered most, preventing surface-level confusion from being overcorrected while deeper structural risks went unaddressed.
ORGANIZE
CONNECT FINDINGS ACROSS TEAMS AND WIPs
In an addendum to the core work, the findings were applied across multiple in-flight initiatives to help teams situate their own decisions within the broader pattern. This cross-application allowed teams to see how similar ambiguity showed up in different contexts, creating shared language for comparison and discussion. Organizing the work this way helped teams connect not just to the data, but to each other—using the research as a common reference point rather than a static artifact.

WORKING THROUGH IMPLICATIONS TOGETHER
Rather than treating the findings as a diagnostic endpoint, the work moved into an active phase of exploration with teams. Research artifacts, evaluation examples, and patterns of ambiguity were brought into working sessions, reviews, and informal discussions, allowing teams to examine how the findings applied to their own in-flight work. This phase treated research not as a verdict, but as material for collective reasoning.
ENGAGING THE MOST IMPACTED TEAMS
Special attention was given to teams whose assumptions, roadmaps, or evaluation practices were most challenged by the findings. Rather than softening conclusions to preserve alignment, the work created space for tension, reflection, and recalibration. By engaging directly with uncertainty (particularly around AI behavior and evaluation,) the work helped teams understand how ambiguity showed up in their own contexts and how it could be addressed without undermining momentum or ownership.
MAKING MISALIGNMENT DISCUSSABLE
Across these engagements, the findings were used to create shared language for discussing where confidence outpaced evidence and where ambiguity had become operationally normalized. Instead of prescribing solutions, the work focused on helping teams articulate what they were assuming, what they were evaluating, and where gaps existed between intent and system behavior. This enabled teams to relate their decisions back to the same set of observations, even when their responses diverged.
ACTION
The work scaled through integration rather than formal adoption. The evaluation criteria, language for discussing ambiguity, and patterns of semantic risk continued to be reused as teams reviewed AI-related work and assessed readiness for reuse or expansion. Because the analysis focused on how meaning moved through systems, rather than on specific tools or implementations, it remained applicable across projects and stages of maturity.
Elements of the work were also shared externally in a broader product and research forum. Presenting the findings in this context tested whether the framing resonated beyond the original teams and reinforced its value as a way to discuss AI behavior, evaluation, and risk without relying on specialized technical language.
Rather than marking an endpoint, scale represented the point at which the work became part of how AI-related decisions were discussed. The shared vocabulary and evaluation lenses supported continued alignment, surfaced disagreement earlier, and reduced the cost of revisiting assumptions as systems evolved.
SCALE

Holli Downs PhD
UX Researcher
See more of my work:

